

Raspberry Pi 活用事例集
Raspberry Pi + Python
Webスクレイピング
Raspberry Pi + Python
Webスクレイピング
ブラウザに表示されるサイトの情報を、プログラムを使って自由に取得できると、エクセルや電子ペーパーへの表示など様々な活用が可能になる。
以下、Raspberry Pi と Python を使って、Webサイトからデータを取得する方法を纏めた。
スポンサー リンク
目 次
1. Webサイトからデータを取得する方法
Linuxコマンド「curl」によるインターネットからの情報収集
curlコマンドはネットワーク経由でのファイルの操作やアップロード・ダウンロードなどを行うためのコマンドで、ネットワークで利用される殆どのプロトコルに対応しているため、インターネットからの情報収集に便利なコマンドとして利用できる。
curl http://www.google.co.jp
curl -I http://www.google.co.jp
curl -I http://www.google.co.jp
-I はcurlコマンドのオプションで、ホームページのHeader情報を取得するコマンド。
APIによるデータの取得
APIとは
「Application Programming Interface」の頭文字をとったもので、「プログラムからアプリケーションを操作するための仕組み」。Web APIとは
あるサイトが備えている機能を、外部からも利用できるように公開するためのインタフェースで、クライアントのプログラムはAPIを提供しているサーバーに対してHTTP/HTTPS方式で通信が可能。天気予報 API(livedoor 天気互換)
気象庁が配信している 全国各地の今日・明日・明後日の天気予報・天気詳細・予想気温・降水確率と都道府県の天気概況情報を JSON データで提供している。
スクレイピングによるデータの取得
スクレイピングとは
「データを収集し、使いやすく加工すること」。
Webスクレイピングは、HTMLから自分が欲しいと思うデータを抽出し取得することで、プログラムでスクレイピングを自動化すれば、データ活用の前準備にかかる手間・時間が大幅に省略可能となる。
2. Python によるスクレイピングのやり方
データを取得する流れ。
①.Requestsで、Webページを取得する
②.BeautifulSoupで、データを取得する
③.select 又は find で、該当箇所を抽出/検索する
②.BeautifulSoupで、データを取得する
③.select 又は find で、該当箇所を抽出/検索する
以下、Yahooの天気予報サイトをスクレイピングしながら、スクレイピングの手順を纏めてみた。

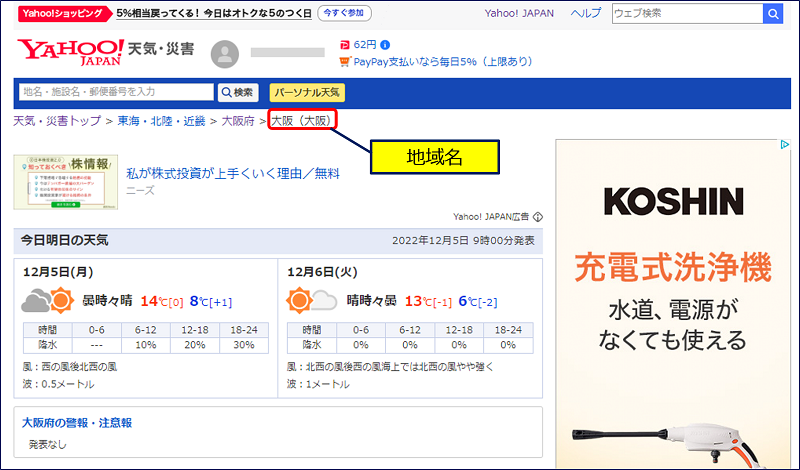
①.Requestsで、Webページを取得する
Pythonのコード。
import requests
url = "'https://weather.yahoo.co.jp/weather/jp/27/6200.html"
info = requests.get(url)
print(info.headers)
print(info.content)コードの説明。
import requests ← Pythonの「Requests」モジュールを使う
url = "'https://weather.yahoo.co.jp/weather/jp/27/6200.html"
← Yahooの天気予報サイト 大阪を指定
info = requests.get(url) ← get()関数でurlを指定すれば、そのページの情報が取得できる
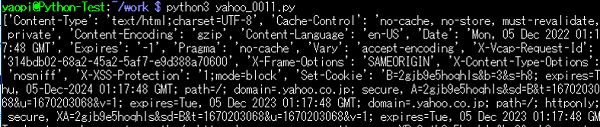
print(info.headers) ← headersで「header情報」が取得できる
print(info.content) ← contentで「body以下のコンテンツ」が取得できる
url = "'https://weather.yahoo.co.jp/weather/jp/27/6200.html"
← Yahooの天気予報サイト 大阪を指定
info = requests.get(url) ← get()関数でurlを指定すれば、そのページの情報が取得できる
print(info.headers) ← headersで「header情報」が取得できる
print(info.content) ← contentで「body以下のコンテンツ」が取得できる
Pythonの実行結果:「header情報」の一部。
②.BeautifulSoupで、データを取得する
BeautifulSoup()の記述方法。
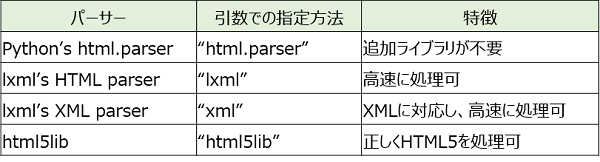
BeautifulSoup(解析対象のHTML/XML, 利用するパーサー)
1つ目の引数には、解析対象のHTML/XMLを渡す。
2つ目の引数には、解析に利用するパーサー(解析器)を指定する。
1つ目の引数には、解析対象のHTML/XMLを渡す。
2つ目の引数には、解析に利用するパーサー(解析器)を指定する。
パーサーの種類。
Pythonのコード。
import requests
from bs4 import BeautifulSoup
url = 'https://weather.yahoo.co.jp/weather/jp/27/6200.html'
resp = requests.get(url)
data = BeautifulSoup(resp.content,"html.parser")
print(data)
コードの説明。
from bs4 import BeautifulSoup
← BeautifulSoupクラスをインポート
data = BeautifulSoup(resp.content,"html.parser")
← respから、BeautifulSoupオブジェクトを作成
print(data)
← 作成された オブジェクト を表示
← BeautifulSoupクラスをインポート
data = BeautifulSoup(resp.content,"html.parser")
← respから、BeautifulSoupオブジェクトを作成
print(data)
← 作成された オブジェクト を表示
Pythonの実行結果:得られた、HTMLファイルをツリー構造で表現したオブジェクト。
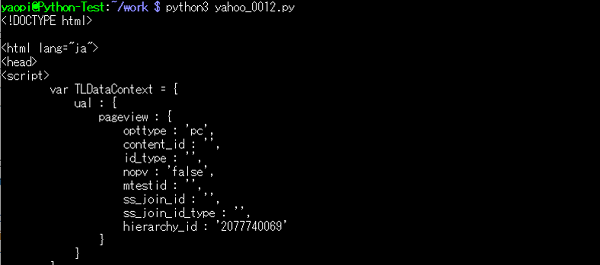
②-1.取得した data をテキスト形式で表示する
Pythonのコード。
print(data.text) ← 取得した data をテキスト形式で表示
Pythonの実行結果:上記の、BeautifulSoupオブジェクトをテキスト形式で表示すると、改行が入っていて見にくい。

②-2.改行を除去して表示する
Pythonのコード。
print(data.text.replace('\n',''))
← 取得した data から、改行を除去して表示Pythonの実行結果:BeautifulSoupオブジェクトのテキストから、改行を除去して表示。
③.selectで、天気予報を抽出する
Pythonのコード。
import requests
from bs4 import BeautifulSoup
url = 'https://weather.yahoo.co.jp/weather/jp/27/6200.html'
resp = requests.get(url)
data1 = BeautifulSoup(resp.text,"html.parser")
data2 = data1.select('#main > div.forecastCity > table > tr > td > div > p.pict')
print(data2)「select()」というメソッドの使い方。
select() 又は select_one()
select('CSSセレクタ’, 'キーワード引数’)
← 抽出条件を引数「'CSSセレクタ’, 'キーワード引数’)」で指定する。
select('CSSセレクタ’, 'キーワード引数’)
← 抽出条件を引数「'CSSセレクタ’, 'キーワード引数’)」で指定する。
コードの説明。
data2 = data1.select('#main > div.forecastCity > table > tr > td > div > p.pict')
← BeautifulSoupで解析した「data1」の中から、
CSSセレクタの階層を辿って該当箇所を指定する。
← BeautifulSoupで解析した「data1」の中から、
CSSセレクタの階層を辿って該当箇所を指定する。
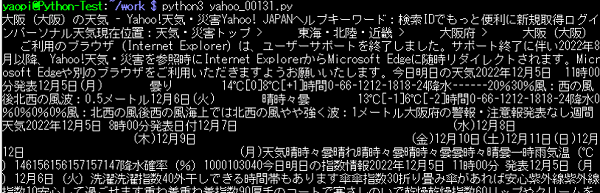
Pythonの実行結果:selectで、天気予報を抽出。

今日の予報と明日の予報の2つが抽出された。
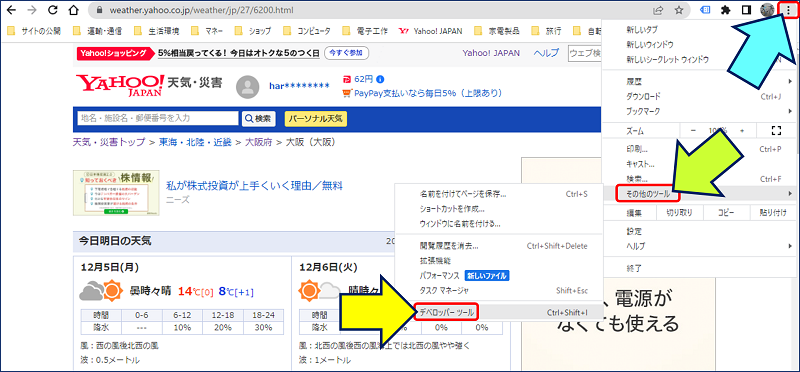
CSSセレクタの調べ方
Google Chromeで該当のページを開き、右上の隅にある縦の三点リーダー「︙」をクリックして「その他のツール」の中から「ディベロッパー ツール」を選択する。
開発者ツールの画面が立ち上がるので、画面左上の矢印をクリックして、Webページ内の調べたい箇所にマウスを持っていくと、画像のように要素の色が変化するのでクリックして確定する。確定した要素を右クリックして「コピー」の中から「selector をコピー」を選択する。
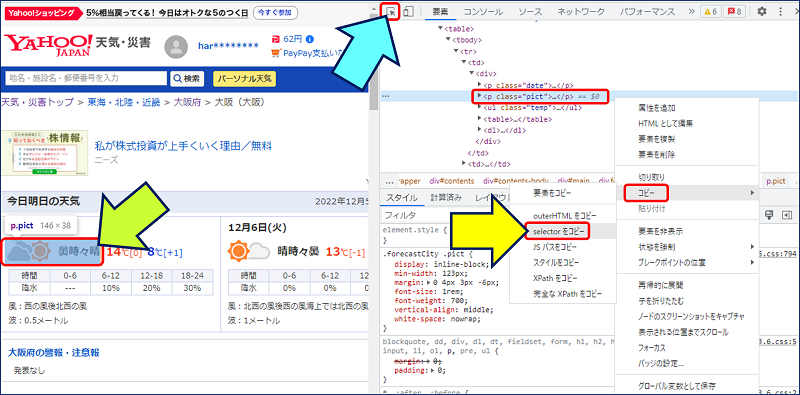
「selector をコピー」した結果。
#main > div.forecastCity > table > tbody > tr > td:nth-child(1) > div > p.pict
Yahooの天気予報サイトにおける、該当箇所のソースコード。
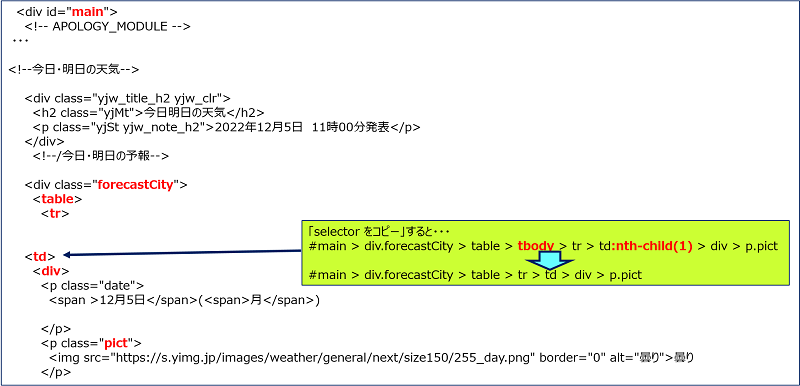
「selector をコピー」した結果には、赤字で示した不要な部分が混ざっているので、除去して使用する。
data2 = data1.select('#main > div.forecastCity > table > tr > td > div > p.pict')
③-1.select_oneで、天気予報を抽出する
Pythonのコード。
data2 = data1.select_one('#main > div.forecastCity > table > tr > td > div > p.pict')
Pythonの実行結果:select_oneで、天気予報を抽出。

今日の予報、1つだけが抽出される。
③-2.抽出した data2 をテキスト形式 & 改行を除去して表示する
Pythonのコード。
print(data2.text.replace('\n',''))
← 抽出した data2 をテキストで、且つ、改行を除去して表示Pythonの実行結果:抽出結果をテキストで、且つ、改行を除去して表示。
3. Yahooの天気予報サイトのスクレイピング
Yahooの天気予報サイトから以下の項目をスクレイピングした例。
・今日の日付
・今日の天気
・今日の最高気温
・今日の最低気温
・明日の天気
・今日の天気
・今日の最高気温
・今日の最低気温
・明日の天気
Pythonの実行結果。

Pythonのコード。
import requests
from bs4 import BeautifulSoup
#アクセスするURL:大阪をセット
url = 'https://weather.yahoo.co.jp/weather/jp/27/6200.html'
#URLにアクセスする:アクセス結果は「resp」に帰ってくる
resp = requests.get(url)
#「resp」らHTMLを取り出して、BeautifulSoupで扱えるようにパースする
soup = BeautifulSoup(resp.text, "html.parser")
#以下、CSSセレクターでHTMLからテキストを取得
#今日の日付
today_date = soup.select_one('#main > div.forecastCity > table > tr > td > div > p.date')
#今日の天気
tenki_today = soup.select_one('#main > div.forecastCity > table > tr > td > div > p.pict')
#今日の最高気温
high_today = soup.select_one('#main > div.forecastCity > table > tr > td > div > ul > li.high')
#今日の最低気温
low_today = soup.select_one('#main > div.forecastCity > table > tr > td > div > ul > li.low')
#明日の天気
tenki_tomorrow = soup.select_one('#main > div.forecastCity > table > tr > td + td > div > p.pict')
#天気の表示
print (today_date.text.replace('\n','')+"の天気")
print ("大阪府今日の天気は"+tenki_today.text.replace('\n',''))
print ("大阪府今日の最高気温は"+high_today.text)
print ("大阪府今日の最低気温は"+low_today.text)
print ("大阪府明日の天気は"+tenki_tomorrow.text.replace('\n',''))コードの説明。
select_one('CSSセレクタ’)
← 全ての項目を、('CSSセレクタ’)を使用して抽出。
← 全ての項目を、('CSSセレクタ’)を使用して抽出。
4. tenki.jp サイトのスクレイピング
「tenki.jp」は、一般財団法人日本気象協会が運営している天気予報を提供するウェブサイトで、市区町村別のピンポイントな天気予報を見ることが出来る。
大阪府八尾市:url = 'https://tenki.jp/forecast/6/30/6200/27212/'
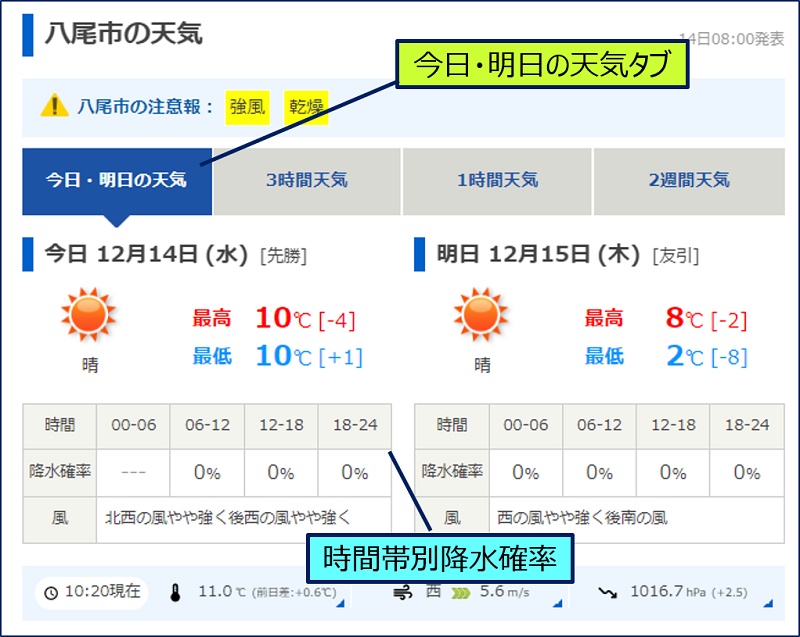
tenki.jp サイトからのスクレイピング項目。
①.市区町村名
以下、今日と明日の日別に
②.日付
③.最高気温(C)
④.最高気温差(C)
⑤.最低気温(C)
⑥.最低気温差(C)
⑦.時間帯別降水確率 [00-06]、[06-12]、[12-18]、[18-24]
⑧.風向
以下、今日と明日の日別に
②.日付
③.最高気温(C)
④.最高気温差(C)
⑤.最低気温(C)
⑥.最低気温差(C)
⑦.時間帯別降水確率 [00-06]、[06-12]、[12-18]、[18-24]
⑧.風向
Pythonのコード。
import re
import requests
from bs4 import BeautifulSoup
# 与えられた日付の解析ページ(p)から、データを抽出して保存する関数
def etl(p):
data = {}
# 日付の抽出
d_pattern = r"(\d+)月(\d+)日\(([土日月火水木金])+\)"
d_src = p.select('.left-style')
date = re.findall(d_pattern, d_src[0].text)[0]
data["date"] = "%s-%s(%s)" % (date[0], date[1], date[2])
print("=====" + data["date"] + "=====")
# 天気予報の抽出
weather = p.select('.weather-telop')[0]
high_temp = p.select("[class='high-temp temp']")[0]
high_temp_diff = p.select("[class='high-temp tempdiff']")[0]
low_temp = p.select("[class='low-temp temp']")[0]
low_temp_diff = p.select("[class='low-temp tempdiff']")[0]
rain_probability = p.select('.rain-probability > td')
wind_wave = p.select('.wind-wave > td')[0]
# データの保存
data["forecasts"] = []
forecast = {}
forecast["weather"] = weather.text.strip()
forecast["high_temp"] = high_temp.text.strip()
forecast["high_temp_diff"] = high_temp_diff.text.strip()
forecast["low_temp"] = low_temp.text.strip()
forecast["low_temp_diff"] = low_temp_diff.text.strip()
every_6h = {}
for i in range(4):
time_from = 0+6*i
time_to = 6+6*i
itr = '{:02}-{:02}'.format(time_from,time_to)
every_6h[itr] = rain_probability[i].text.strip()
forecast["rain_probability"] = every_6h
forecast["wind_wave"] = wind_wave.text.strip()
data["forecasts"].append(forecast)
print(
"天気 : " + forecast["weather"] + "\n"
"最高気温(C) : " + forecast["high_temp"] + "\n"
"最高気温差(C) : " + forecast["high_temp_diff"] + "\n"
"最低気温(C) : " + forecast["low_temp"] + "\n"
"最低気温差(C) : " + forecast["low_temp_diff"] + "\n"
"降水確率[00-06] : " + forecast["rain_probability"]['00-06'] + "\n"
"降水確率[06-12] : " + forecast["rain_probability"]['06-12'] + "\n"
"降水確率[12-18] : " + forecast["rain_probability"]['12-18'] + "\n"
"降水確率[18-24] : " + forecast["rain_probability"]['18-24'] + "\n"
"風向 : " + forecast["wind_wave"] + "\n"
)
return data
# 関数はここまで
# 「pythonファイル名.py」形式で実行されているかどうかの判定
if __name__ == '__main__':
# これ以降の処理を実行
# アクセスするURL:日本気象協会 tenki.jp 大阪府八尾市を設定する
url = 'https://tenki.jp/forecast/6/30/6200/27212/'
# URLにアクセスしデータを取得する。結果は「resp1」に格納する
resp1 = requests.get(url)
#「resp1」のエンコーディング方式(UTF-8)で、
#「resp1.text」をエンコードし「html」に格納する
html = resp1.text.encode(resp1.encoding)
#BeautifulSoup のパーサー「lxml:高速処理」を利用して解析ページを作成する
resp2 = BeautifulSoup(html, 'lxml')
# 解析ページを保存するテーブルを用意する
kaiseki = {}
# 予測地点を取得する要素のパターンを指定する
y_pattern = r"(.+)の今日明日の天気"
# 指定した要素にある「title」から地域名を取得する
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
# 取得した地域名を表示する
print(kaiseki['tiiki'] + "の天気")
# 関数に渡すパラメータに今日の「天気予報ページ」をセット
p_tdy = resp2.select('.today-weather')[0]
# 関数に渡すパラメータに明日の「天気予報ページ」をセット
p_tmr = resp2.select('.tomorrow-weather')[0]
# 関数を使って今日のデータ抽出して保存
kaiseki["today"] = etl(p_tdy)
# 関数を使って明日のデータ抽出して保存
kaiseki["tomorrow"] = etl(p_tmr)Pythonの実行結果:
1. 正規表現に関するコードの説明
import re ← Pythonの「正規表現を行う」モジュールを使う
#「resp1.text」をエンコードし「html」に格納する
html = resp1.text.encode(resp1.encoding)
resp2 = BeautifulSoup(html, 'lxml')
← エンコードした「html」をBeautifulSoup のコンストラクタに渡す
# 指定した要素にある「title」から地域名を取得する
y_pattern = r"(.+)の今日明日の天気"
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
← 「title」から「の今日明日の天気」の前にある地域名を抽出
#「resp1.text」をエンコードし「html」に格納する
html = resp1.text.encode(resp1.encoding)
resp2 = BeautifulSoup(html, 'lxml')
← エンコードした「html」をBeautifulSoup のコンストラクタに渡す
# 指定した要素にある「title」から地域名を取得する
y_pattern = r"(.+)の今日明日の天気"
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
← 「title」から「の今日明日の天気」の前にある地域名を抽出
1-1. BeautifulSoup のコンストラクタのエンコード。
resp2 = BeautifulSoup(resp1, 'lxml')
→ 「TypeError: object of type 'Response' has no len()」
エンコードしないでBeautifulSoup のコンストラクタに渡すとエラーになる。
resp2 = BeautifulSoup(resp1.content, 'lxml')
← このように、Response オブジェクトではなく、
応答内容を持つバイト列を渡せばOK。
→ 「TypeError: object of type 'Response' has no len()」
エンコードしないでBeautifulSoup のコンストラクタに渡すとエラーになる。
resp2 = BeautifulSoup(resp1.content, 'lxml')
← このように、Response オブジェクトではなく、
応答内容を持つバイト列を渡せばOK。
1-2. re.findall関数と正規表現。
y_pattern = r"(.+)の今日明日の天気"
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
← re.findall関数を使って正規表現のマッチング処理を行い、
文字列から部分文字列を抽出する。
<title>八尾市の今日明日の天気 - 日本気象協会 tenki.jp</title>
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
← re.findall関数を使って正規表現のマッチング処理を行い、
文字列から部分文字列を抽出する。
<title>八尾市の今日明日の天気 - 日本気象協会 tenki.jp</title>
ソースコードの「title」の内容。

2. 関数に関するコードの説明
# 与えられた日付の解析ページ(p)から、データを抽出して保存する関数
def etl(p): ← 関数の定義:関数名 etl 、引数 (p)
data = {}
.....
return data ← 関数の終わり data に戻り値を返す
# 関数はここまで
------------------------------------------------------------
# 関数の呼び出し
kaiseki["today"] = etl(p_tdy) ← 引数 (p)に今日のページをセット
kaiseki["tomorrow"] = etl(p_tmr) ← 引数 (p)に明日のページをセット
def etl(p): ← 関数の定義:関数名 etl 、引数 (p)
data = {}
.....
return data ← 関数の終わり data に戻り値を返す
# 関数はここまで
------------------------------------------------------------
# 関数の呼び出し
kaiseki["today"] = etl(p_tdy) ← 引数 (p)に今日のページをセット
kaiseki["tomorrow"] = etl(p_tmr) ← 引数 (p)に明日のページをセット
今日の天気と明日の天気を抽出するためには、同じ処理を2回実行する必要がある。そこで、この処理を関数にして、日付別に呼び出して実行すれば、コードは1回のみの記述でよく、簡潔になる。
3. データの保存場所に関するコードの説明
データ保存用配列(array)の構造。
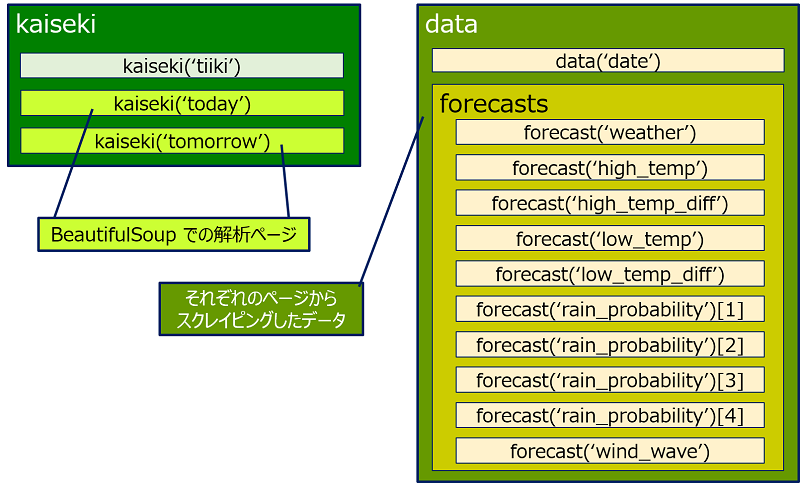
# 解析ページを保存するテーブルを用意する
kaiseki = {}
------------------------------------------------------------
# 関数
def etl(p):
data = {}
.....
# データの保存
data["forecasts"] = []
forecast = {}
kaiseki = {}
------------------------------------------------------------
# 関数
def etl(p):
data = {}
.....
# データの保存
data["forecasts"] = []
forecast = {}
4. if __name__ == “__main__” とは
# 「pythonファイル名.py」形式で実行されているかどうかの判定
if __name__ == '__main__':
# これ以降の処理を実行
← Pythonファイルが「pythonファイル名.py」という形で実行されると、
これ以降のコードが処理される
if __name__ == '__main__':
# これ以降の処理を実行
← Pythonファイルが「pythonファイル名.py」という形で実行されると、
これ以降のコードが処理される
この行より上部には「関数」の内容を記述しているので、実行はこれ以降の処理を行えばよい。
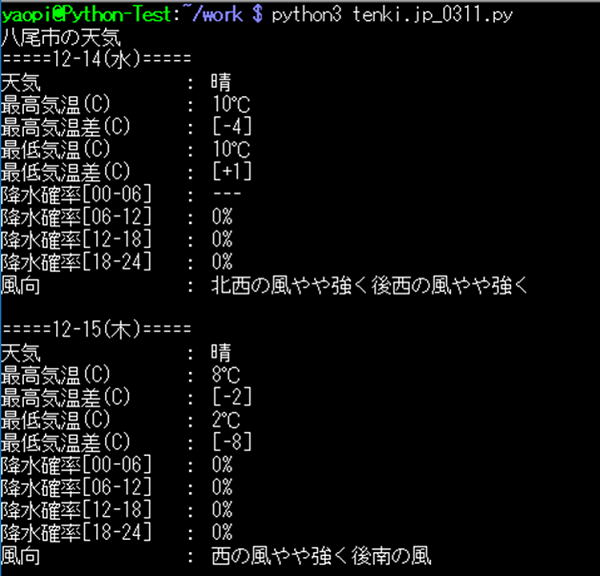
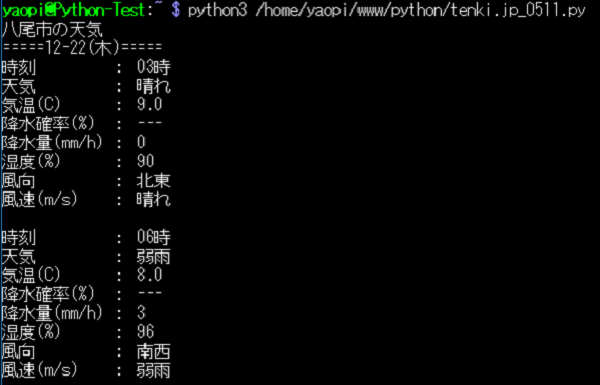
5. tenki.jp 3時間天気のスクレイピング
tenki.jp サイトに於ける、3時間天気のタブ。
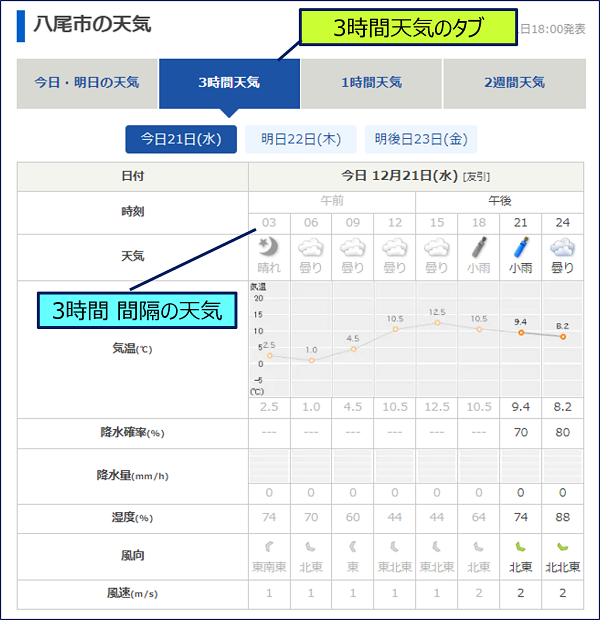
3時間天気タブから、スクレイピングした項目。
・日付
・時刻
・天気
・気温(C)
・降水確率(%)
・降水量(mm/h)
・湿度(%)
・風向
・風速
・時刻
・天気
・気温(C)
・降水確率(%)
・降水量(mm/h)
・湿度(%)
・風向
・風速
Pythonの実行結果。
Pythonのコード。
import re
import requests
from bs4 import BeautifulSoup
# 与えられた日付の解析ページ(p)から、データを抽出して保存する関数
def etl(p):
data = {}
# 日付の抽出
d_pattern = r"(\d+)月(\d+)日\(([土日月火水木金])+\)"
d_src = p.select('.head p')
date = re.findall(d_pattern, d_src[0].text)[0]
data["date"] = "%s-%s(%s)" % (date[0], date[1], date[2])
print("=====" + data["date"] + "=====")
# 一時間ごとの天気予報の抽出
hour = p.select('.hour > td')
weather = p.select('.weather > td')
temperature = p.select('.temperature > td')
prob_precip = p.select('.prob-precip > td')
precipitation = p.select('.precipitation > td')
humidity = p.select('.humidity > td')
wind_blow = p.select('.wind-direction > td')
wind_speed = p.select('.wind-speed > td')
## 格納
data["forecasts"] = []
for itr in range(0, 8):
forecast = {}
forecast["hour"] = hour[itr].text.strip()
forecast["weather"] = weather[itr].text.strip()
forecast["temperature"] = temperature[itr].text.strip()
forecast["prob-precip"] = prob_precip[itr].text.strip()
forecast["precipitation"] = precipitation[itr].text.strip()
forecast["humidity"] = humidity[itr].text.strip()
forecast["wind_blow"] = wind_blow[itr].text.strip()
forecast["wind-speed"] = wind_speed[itr].text.strip()
data["forecasts"].append(forecast)
print(
"時刻 : " + forecast["hour"] + "時" + "\n"
"天気 : " + forecast["weather"] + "\n"
"気温(C) : " + forecast["temperature"] + "\n"
"降水確率(%) : " + forecast["prob-precip"] + "\n"
"降水量(mm/h) : " + forecast["precipitation"] + "\n"
"湿度(%) : " + forecast["humidity"] + "\n"
"風向 : " + forecast["wind_blow"] + "\n"
"風速(m/s) : " + forecast["weather"] + "\n"
)
return data
def etl2(p):
data = {}
# 日付の抽出
d_pattern = r"(\d+)月(\d+)日\(([土日月火水木金])+\)"
d_src = p.select('.head p')
date = re.findall(d_pattern, d_src[0].text)[0]
data["date"] = "%s-%s(%s)" % (date[0], date[1], date[2])
print("=====" + data["date"] + "=====")
# 一時間ごとの天気予報の抽出
hour = p.select('.hour > td')
weather = p.select('.weather > td')
temperature = p.select('.temperature > td')
prob_precip = p.select('.prob-precip > td')
precipitation = p.select('.precipitation > td')
humidity = p.select('.humidity > td')
wind_blow = p.select('.wind-blow > td')
wind_speed = p.select('.wind-speed > td')
## 格納
data["forecasts"] = []
for itr in range(0, 8):
forecast = {}
forecast["hour"] = hour[itr].text.strip()
forecast["weather"] = weather[itr].text.strip()
forecast["temperature"] = temperature[itr].text.strip()
forecast["prob-precip"] = prob_precip[itr].text.strip()
forecast["precipitation"] = precipitation[itr].text.strip()
forecast["humidity"] = humidity[itr].text.strip()
forecast["wind_blow"] = wind_blow[itr].text.strip()
forecast["wind-speed"] = wind_speed[itr].text.strip()
data["forecasts"].append(forecast)
print(
"時刻 : " + forecast["hour"] + "時" + "\n"
"天気 : " + forecast["weather"] + "\n"
"気温(C) : " + forecast["temperature"] + "\n"
"降水確率(%) : " + forecast["prob-precip"] + "\n"
"降水量(mm/h) : " + forecast["precipitation"] + "\n"
"湿度(%) : " + forecast["humidity"] + "\n"
"風向 : " + forecast["wind_blow"] + "\n"
"風速(m/s) : " + forecast["weather"] + "\n"
)
return data
# 関数はここまで
# 「pythonファイル名.py」形式で実行されているかどうかの判定
if __name__ == '__main__':
# これ以降の処理を実行
# アクセスするURL:日本気象協会 tenki.jp 大阪府八尾市の3時間天気を設定する
url = 'https://tenki.jp/forecast/6/30/6200/27212/3hours.html'
# URLにアクセスしデータを取得する。結果は「resp1」に格納する
resp1 = requests.get(url)
#「resp1」のエンコーディング方式(UTF-8)で、
#「resp1.text」をエンコードし「html」に格納する
html = resp1.text.encode(resp1.encoding)
#BeautifulSoup のパーサー「lxml:高速処理」を利用して解析ページを作成する
resp2 = BeautifulSoup(html, 'lxml')
# 解析ページを保存するテーブルを用意する
kaiseki = {}
# 予測地点を取得する要素のパターンを指定する
y_pattern = r"(.+)の3時間天気"
# 指定した要素にある「title」から地域名を取得する
kaiseki['tiiki'] = re.findall(y_pattern, resp2.title.text)[0]
# 取得した地域名を表示する
print(kaiseki['tiiki'] + "の天気")
# 関数に渡すパラメータに今日の「天気予報ページ」をセット
p_tdy = resp2.find(id='forecast-point-3h-today')
p_tmr = resp2.find(id='forecast-point-3h-tomorrow')
p_dat = resp2.find(id='forecast-point-3h-dayaftertomorrow')
# 関数を使ってデータ抽出して保存
kaiseki["today"] = etl(p_tdy)
kaiseki["tomorrow"] = etl2(p_tmr)
kaiseki["dayaftertomorrow"] = etl2(p_dat)関数を「2つ」用意した理由。
風向に関する 'CSSセレクタ’ が、日で異なっている
→ 今日 <tr class="wind-direction">
→ 明日と明後日 <tr class="wind-blow">
→ 今日 <tr class="wind-direction">
→ 明日と明後日 <tr class="wind-blow">
6. まとめ
1. スクレイピングのやり方。
①.Requestsで、Webページを取得する
②.BeautifulSoupで、データを取得する
③.select 又は find で、該当箇所を抽出/検索する
②.BeautifulSoupで、データを取得する
③.select 又は find で、該当箇所を抽出/検索する
2. CSSセレクタの調べ方。
HTML要素を取得するselect() メソッドで指定する「CSSセレクタ」は、「ディベロッパー ツール」を使えば簡単に調べられるが、変更が必要。
3. 正規表現について。
①.BeautifulSoup のコンストラクタのエンコード
②.re.findall関数と正規表現
②.re.findall関数と正規表現
4. Python テキスト形式で、且つ、改行を除去して表示する方法。
print(data.text.replace('\n',''))
5. Python 関数と「if __name__ == “__main__”」について。
以上。
(2022.12.11)
(2022.12.11)
スポンサー リンク