

Webサーバー サイトの管理
nginx リバース プロキシ サーバー
AIクローラーのブロックとトラフィックの監視
nginx リバース プロキシ サーバー
AIクローラーのブロックとトラフィックの監視
最近 AIクローラーのユーザーエージェントによるアクセスが急増し、Webサーバーのレスポンスに影響を及ぼすようになった。
「meta-externalagent」と「GPTBot」。
「meta-externalagent」と「GPTBot」。
以下、ユーザーエージェントでのブロック方法とトラフィックの監視要領をまとめた。
スポンサー リンク
目 次
1. クローラーとユーザーエージェントについて
クローラーとは、
インデックスを作成することを目的にした、サイトを巡回するロボット(bot、またはスパイダーとも呼ばれる)のこと。
ユーザーエージェント(User-Agent) とは、
インターネットを閲覧しているユーザーの、デバイス・OS・ブラウザなどの情報を文字列にしたもの。
ユーザーエージェントの文字列。
User-Agent: <product> / <product-version> <comment> (<system-information>) <platform> (<platform-details>) <extensions>
ユーザーエージェントは、ウェブサイトを巡回して情報を収集する際に使用されるデバイス・OS・ブラウザなどの情報で、Googleのウェブクローラーの場合次のような種類がある。
WindowsPC:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0
MacPC:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
LinuxPC:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36
モバイル:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.6778.69 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.6778.69 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
2. nginx で クローラーをブロックする設定
リバースプロキシにおけるnginxの設定要件。

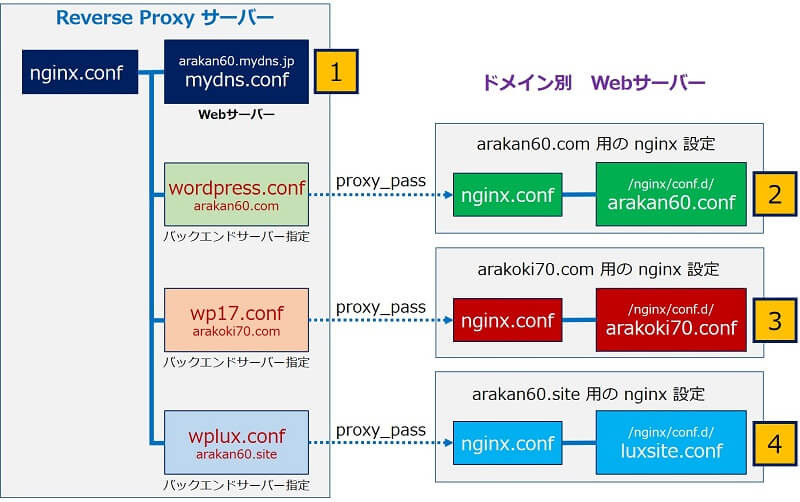
Reverse Proxy サーバーが、バックエンドのWebサーバーに振り分けるために記述している「proxy_pass」の前に記述。(内容は外出しにした。)

# ユーザーエージェントが指定の文字列を含む場合にアクセスを拒否
include conf.d/sotodasi/agent-block.conf;agent-block.conf での、クローラーをブロックする記述。
「meta-externalagent」と「GPTBot」をブロック。
「meta-externalagent」と「GPTBot」をブロック。
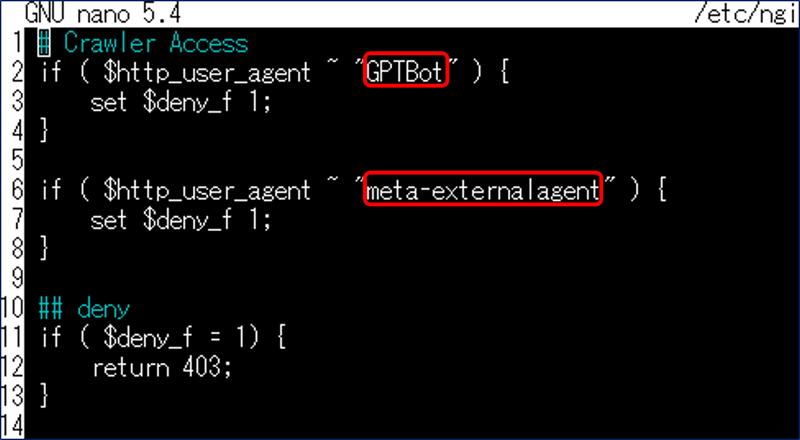
# Crawler Access
if ( $http_user_agent ~ "GPTBot" ) {
set $deny_f 1;
}
if ( $http_user_agent ~ "meta-externalagent" ) {
set $deny_f 1;
}
## deny
if ( $deny_f = 1) {
return 403;
}3. User-Agent別・Host別アクセス回数の監視
どのような「User-Agent」がどのサイトにアクセスしているかを調べるために、アクセスログを次のようなフォーマットにカスタマイズ。

# アクセスログをカスタムフォーマットに変更
log_format custom '$host - $remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent"';
access_log /var/log/nginx/custom_access.log custom;先頭に「$host」を出力し、どのサイトへのアクセスなのかが一目でわかるようにした。
User-Agent別・Host別のアクセス回数を集計して表示する、Pythonスクリプトを作成。
import re
from collections import defaultdict, Counter
# ログファイルのパス
log_file_path = "/var/log/nginx/custom_access.log"
# クローラー名とその正規表現パターンの辞書
crawler_patterns = {
'Seekport': r'SeekportBot',
'Gecko': r'Gecko',
'GPT': r'GPTBot',
'bing': r'bingbot',
'peer39': r'peer39_crawler',
'proximic': r'proximic',
'metafetch': r'meta-externalfetcher',
'facemeta': r'meta-externalagent',
'facebot': r'facebookexternalhit',
'Apple': r'AppleWebKit',
'Ahrefs': r'AhrefsBot',
'Googlebot': r'Googlebot',
'Google-Image': r'Googlebot-Image',
'Firefox': r'Gecko',
'DotBot': r'DotBot',
'GrapeshotCrawler': r'GrapeshotCrawler',
'ias-ie': r'ias-ie',
'Barkrowler': r'Barkrowler',
'BLEXBot': r'BLEXBot',
'Mediapartners': r'Mediapartners',
'Twitterbot': r'Twitterbot',
'proximic': r'proximic',
'ias-va': r'ias-va',
'MJ12bot': r'MJ12bot',
'Go-http-client': r'Go-http-client',
'MSIE': r'MSIE',
'Y!J-ASR': r'Y!J-ASR',
'SemrushBot': r'SemrushBot',
'FeedBurner': r'FeedBurner',
'zgrab': r'zgrab',
'CriteoBot': r'CriteoBot'
}
# 正規表現パターン(指定されたフォーマットに対応)
log_pattern = re.compile(
r'(?P[^\s]+) - [^\s]+ - [^\s]+ \[[^\]]+\] "[^"]*" '
r'[0-9]+ [0-9]+ "[^"]*" "(?P[^"]+)"'
)
# ネストされた辞書を準備(クローラー名ごとにHostのカウントを格納)
crawler_host_counter = defaultdict(Counter)
# ログファイルを読み込む
with open(log_file_path, "r") as log_file:
for line in log_file:
match = log_pattern.match(line)
if match:
host = match.group("host")
user_agent = match.group("user_agent")
# クローラー名の判定
matched = False
for crawler_name, pattern in crawler_patterns.items():
if re.search(pattern, user_agent):
crawler_host_counter[crawler_name][host] += 1
matched = True
break # 最初にマッチしたクローラー名でカウントする
# 未知のクローラー(Unknown)に記録
if not matched:
crawler_host_counter["Unknown"][host] += 1
# クローラーごとの合計値を計算
crawler_totals = {crawler: sum(host_counts.values()) for crawler, host_counts in crawler_host_counter.items()}
# 合計値で降順にソート
sorted_crawler_totals = sorted(crawler_totals.items(), key=lambda x: x[1], reverse=True)
# 結果を出力
print("クローラー別 Hostごとのアクセス回数(合計値の降順):")
for crawler_name, total in sorted_crawler_totals:
print(f"\nクローラー: {crawler_name} (合計: {total})")
for host, count in crawler_host_counter[crawler_name].most_common():
print(f" {host}: {count}")クローラー名とその正規表現パターンの辞書を用意して、マッチングを行う処理とした。
Pythonスクリプトの実行結果。アクセス回数の降順に表示。
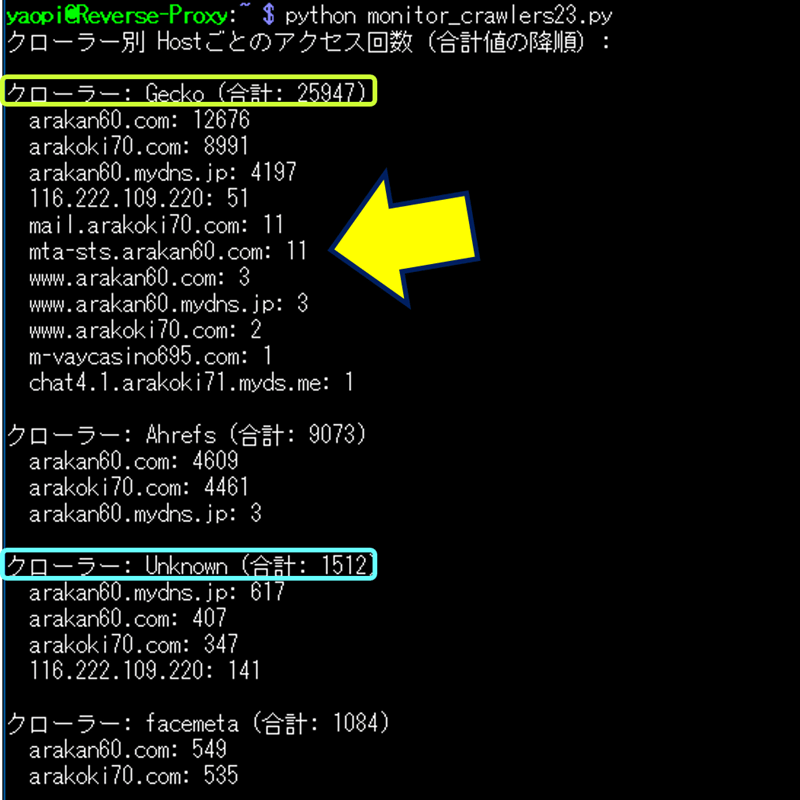
クローラー名辞書にマッチしなかったクローラーは「Unknown」に表示されるので、この値が大きくなれば次の「User-Agent調査」を行い、クローラーを特定して辞書に追記を行う。
4. User-Agent名の一覧表示
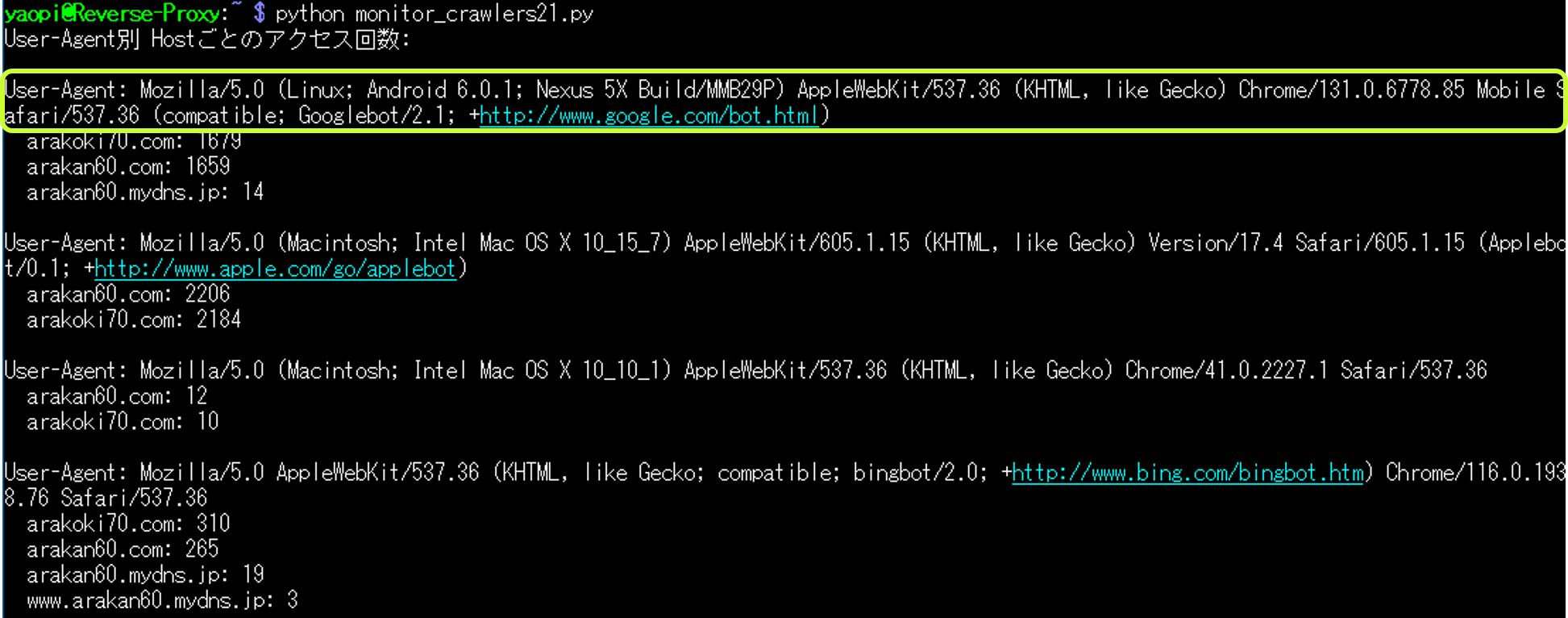
アクセス回数の多い「User-Agent名」を調べるために、「User-Agent名」をフルで表示するPythonスクリプトを作成した。
import re
from collections import defaultdict, Counter
# ログファイルのパスを指定
log_file_path = "/var/log/nginx/custom_access.log"
# 正規表現パターン(指定されたフォーマットに対応)
log_pattern = re.compile(
r'(?P[^\s]+) - [^\s]+ - [^\s]+ \[[^\]]+\] "[^"]*" '
r'[0-9]+ [0-9]+ "[^"]*" "(?P[^"]+)"'
)
# ネストされた辞書を準備(User-AgentごとにHostのカウントを格納)
user_agent_host_counter = defaultdict(Counter)
# ログファイルを読み込む
with open(log_file_path, "r") as log_file:
for line in log_file:
match = log_pattern.match(line)
if match:
host = match.group("host")
user_agent = match.group("user_agent")
# ネストされたカウンターに記録
user_agent_host_counter[user_agent][host] += 1
# 結果を出力
print("User-Agent別 Hostごとのアクセス回数:")
for user_agent, host_counter in user_agent_host_counter.items():
print(f"\nUser-Agent: {user_agent}")
for host, count in host_counter.most_common():
print(f" {host}: {count}")Pythonスクリプトの実行結果。
Host毎のアクセス回数も表示している。
User-Agent名を一覧表示した一部サンプル。
User-Agent別:
User-Agent: meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)
arakan60.com: 62368
arakoki70.com: 61754
User-Agent: Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.6778.69 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
arakan60.com: 710
arakoki70.com: 707
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot)
arakan60.com: 43
arakoki70.com: 265. アクセスログを参照するコマンド
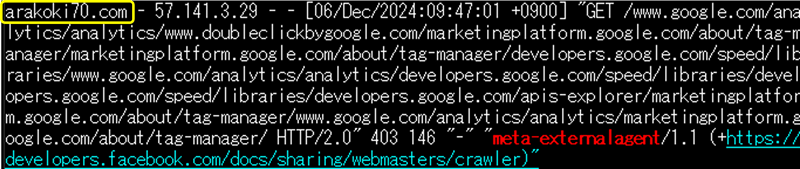
■$host による抽出。
grep 'arakan60.com' /var/log/nginx/custom_access.log | grep 'meta-externalagent'
■特定の1分間 (20:40台) のログを表示。
grep '\[04/Dec/2024:20:40:' /var/log/nginx/custom_access.log
■時間範囲 (例えば、20:00〜20:59) を指定して表示。
awk '/\[04\/Dec\/2024:20:/{print}' /var/log/nginx/custom_access.log
■リアルタイムでの監視。
tail -f /var/log/nginx/custom_access.log | grep 'meta-externalagent'
以上。
(2024.12.05)
(2024.12.05)
スポンサー リンク