

Webサーバー サイトの管理
nginx
User-Agentを持つリクエストのブロック
nginx
User-Agentを持つリクエストのブロック
Webサーバーに対してFacebookのユーザーエージェント「facebookexternalhit」が大量にリクエストされ、インターネットの上り(アップロード)データが1日あたり 30GBを超える事態が続いた。
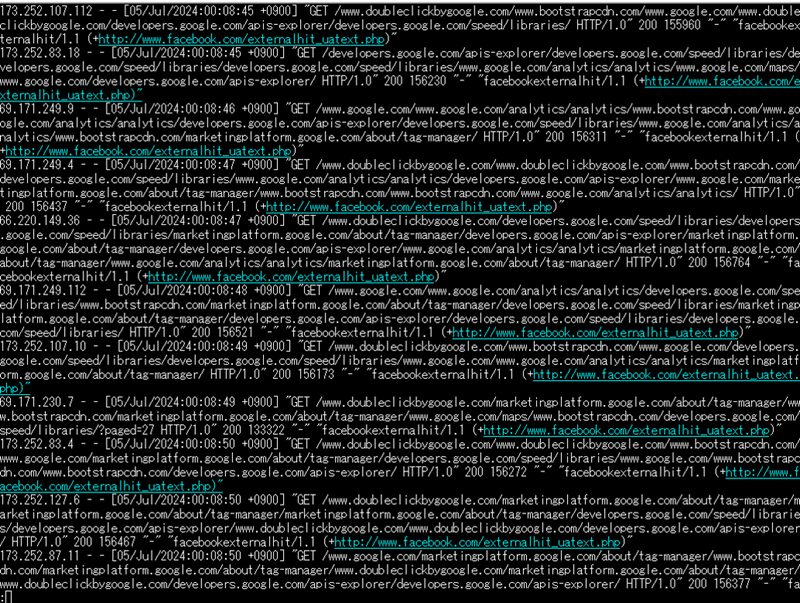
nginxのアクセスログが、ユーザーエージェント「facebookexternalhit」で占拠された。
以下、nginxで特定のユーザーエージェントを拒否する設定と、クローラートラフィックを監視するためのカスタムスクリプトを作成した記録。
スポンサー リンク
目 次
1. ユーザーエージェントをブロックするに至った経緯
J:COMより内容証明の郵便物が届く。


大量のデータ送信(※) が確認されましたとのこと。
「NETサービスにおける大量データ送信に関する見直しのお願い」
※大量データ送信とは、お客さまのパソコンなどからインターネット網に送信される1日あたり 30GB(ギガ バイト)以上の上り(アップロード)データ通信と定義しています。
※大量データ送信とは、お客さまのパソコンなどからインターネット網に送信される1日あたり 30GB(ギガ バイト)以上の上り(アップロード)データ通信と定義しています。
大量のデータをアップロードしたりクラウドサービスを利用したこともないため、原因が分からず、取り敢えず稼働中のWebサーバーを止める。
2日間程Webサーバーを止めた後、J:COMのサポートセンターに確認すると、30Gを下回っているとのこと。
これで、原因はWebサーバーにあると特定する。
これで、原因はWebサーバーにあると特定する。
この間に「上りのデータ量」を測定する方法を調査するも、適切な方法が見当たらず、唯一の手掛かりとして、ルーターの機能で通信パケット数が把握できることが判明したので、パケット数の推移を測定してみる。
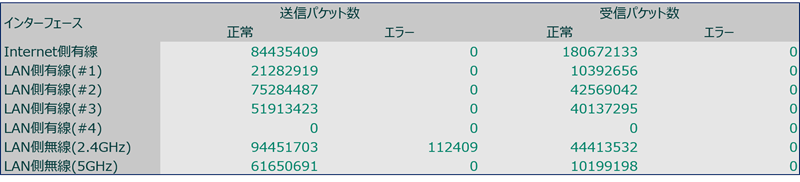
Webサーバーの稼働時と停止時における上りのパケット数を比較してみるも、平常時と異常時のパケット数の差がどれぐらいであれば「異常値」なのかが分からず、苦戦する。
その後、4つあるサーバーの内の1つに「nginxのアクセスログ」が書き出されており、内容を見ると "facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)"
という、Facebookのクローラーが大量に来ていることに気付く。
という、Facebookのクローラーが大量に来ていることに気付く。
早速、nginxの設定ファイルでこのクローラーをブロックする。
これで「大量データ送信問題」を解決することが出来た。
これで「大量データ送信問題」を解決することが出来た。
此処に至るまでに、6日間も要することになり、通常は「nginxのアクセスログ」を停止ているが、トラブルがあれば「nginxのアクセスログを見る」のが先決と再認識する。
2. nginxでクローラーをブロックする方法
/etc/nginx/conf.d/にある設定ファイルの、サーバーブロック(serverブロック)内に下記を記述。
server {
listen 80;
server_name example.com;
...
location / {
if ($http_user_agent ~* (facebookexternalhit|Facebot)) {
return 403;
}
...
}
...
}この設定により、User-Agentが「facebookexternalhit」であるリクエストには 403 Forbiddenを返すようになる。
設定を保存してnginxを再起動する。
sudo nginx -t
sudo nginx -s reload
sudo systemctl restart nginx
sudo nginx -s reload
sudo systemctl restart nginx
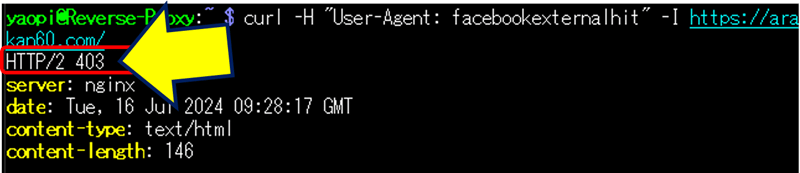
ユーザーエージェントがブロックされたか確認する。
curl -H "User-Agent: facebookexternalhit" -I https://ドメイン名/
403 が返ってくることを確認。
3. クローラーのユーザエージェントをブロックする問題点
利点
サーバー負荷の軽減:
クローラーによる頻繁なアクセスを防ぐことで、サーバーへの負荷を軽減することがでる。
クローラーによる頻繁なアクセスを防ぐことで、サーバーへの負荷を軽減することがでる。
問題点
1. リンクプレビューの生成ができない:
ウェブサイトのリンクがシェアされた際に、リンクプレビュー(タイトル、説明文、サムネイル画像)が生成されない為、投稿の見栄えが悪くなりクリック率が低下する可能性がある。
ウェブサイトのリンクがシェアされた際に、リンクプレビュー(タイトル、説明文、サムネイル画像)が生成されない為、投稿の見栄えが悪くなりクリック率が低下する可能性がある。
2. シェアの効果が減少:
ウェブサイトのリンクをシェアする際にリンクプレビューが生成されないと、その投稿が魅力的でなくなり、結果的にシェアの効果が減少する。
ウェブサイトのリンクをシェアする際にリンクプレビューが生成されないと、その投稿が魅力的でなくなり、結果的にシェアの効果が減少する。
対策
クローラートラフィックの監視:
ブロックする前に、クローラーによるトラフィックを監視し、その影響を評価する。(トラフィックが異常値でなければブロックしない。)
ブロックする前に、クローラーによるトラフィックを監視し、その影響を評価する。(トラフィックが異常値でなければブロックしない。)
4. クローラートラフィックの監視要領
クローラートラフィックを監視するための「カスタムスクリプト」を作成する。
Nginxのログファイルから、
ユーザーエージェント別のリクエスト件数を集計して一覧表示し、
ユーザーエージェント別のトラフィックを監視する。
ユーザーエージェント別のリクエスト件数を集計して一覧表示し、
ユーザーエージェント別のトラフィックを監視する。
1. Nginxのログフォーマットのカスタマイズ
Nginxの設定ファイルは /etc/nginx/nginx.conf ファイルを編集し、ログにユーザーエージェント情報を含めるようにカスタマイズする。
http {
log_format custom '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent"';
access_log /var/log/nginx/custom_access.log custom;
# その他の設定
server {
# サーバ設定
}
}
この設定により、/var/log/nginx/custom_access.log にカスタムフォーマットのログが記録される。
2. カスタムスクリプトの作成
①.特定のユーザーエージェント(例:facebookexternalhit)を持つ行を抽出するPythonスクリプト。
import re
# Nginxのカスタムログファイルパス
log_file_path = '/var/log/nginx/custom_access.log'
# 監視するクローラーのユーザーエージェント
crawler_user_agent = 'facebookexternalhit'
# ログファイルを開いて、該当する行を抽出
with open(log_file_path, 'r') as log_file:
for line in log_file:
if re.search(crawler_user_agent, line):
print(line)②.ユーザーエージェント別のアクセス件数を一覧表示するPythonスクリプト
import re
from collections import Counter
# Nginxのカスタムログファイルパス
log_file_path = '/var/log/nginx/custom_access.log'
# ユーザーエージェントの出現回数をカウントする変数
user_agent_counter = Counter()
# ログファイルを開いて、ユーザーエージェントを抽出
with open(log_file_path, 'r') as log_file:
for line in log_file:
# ユーザーエージェント部分を抽出する正規表現
match = re.search(r'"([^"]*)"$', line)
if match:
user_agent = match.group(1)
user_agent_counter[user_agent] += 1
# ユーザーエージェント別の件数を表示
for user_agent, count in user_agent_counter.most_common():
print(f'"{user_agent}": {count} accesses')③.ブラウザーや端末タイプを除外して、ユーザーエージェントのみで集計するPythonスクリプト。
import re
from collections import Counter
import datetime
t_delta = datetime.timedelta(hours=9)
JST = datetime.timezone(t_delta, 'JST')
now = datetime.datetime.now(JST)
# Nginxのカスタムログファイルパス
log_file_path = '/var/log/nginx/custom_access.log'
# ユーザーエージェントのパターンとカウントするための辞書
crawler_patterns = {
'facebot': r'facebookexternalhit',
'Apple': r'AppleWebKit',
'Ahrefs': r'AhrefsBot',
'Googlebot': r'Googlebot',
# 'Google-Image': r'Googlebot-Image',
# 'Google-Image': r'"Googlebot-Image/1.0"',
'Firefox': r'Gecko',
'DotBot': r'DotBot',
'GrapeshotCrawler': r'GrapeshotCrawler',
'ias-ie': r'ias-ie',
'Barkrowler': r'Barkrowler',
'BLEXBot': r'BLEXBot',
'Mediapartners': r'Mediapartners',
'Twitterbot': r'Twitterbot',
'proximic': r'proximic',
'ias-va': r'ias-va',
'MJ12bot': r'MJ12bot',
'Go-http-client': r'Go-http-client',
'MSIE': r'MSIE',
'Y!J-ASR': r'Y!J-ASR',
'SemrushBot': r'SemrushBot',
'FeedBurner': r'FeedBurner',
'zgrab': r'zgrab',
'CriteoBot': r'CriteoBot'
}
# ユーザーエージェントの出現回数をカウントする変数
crawler_counter = Counter()
# ログファイルを開いて、ユーザーエージェントを抽出
with open(log_file_path, 'r') as log_file:
for line in log_file:
# ユーザーエージェント部分を抽出する正規表現
match = re.search(r'"([^"]*)"$', line)
if match:
user_agent = match.group(1)
for crawler, pattern in crawler_patterns.items():
if re.search(pattern, user_agent, re.IGNORECASE):
crawler_counter[crawler] += 1
break
# YYYY/MM/DD hh:mm:ss形式に書式化
d = now.strftime('%Y/%m/%d %H:%M:%S')
print(d) # 2021/11/04 17:37:28
# ユーザーエージェント別の件数を表示
for crawler, count in crawler_counter.most_common():
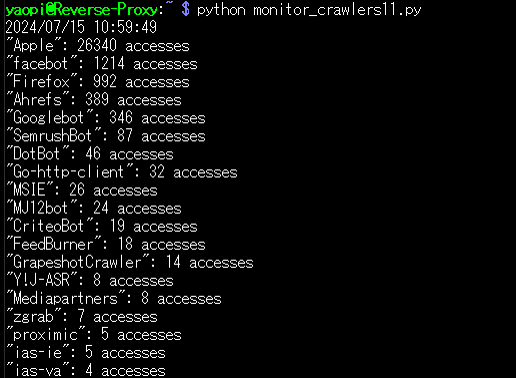
print(f'"{crawler}": {count} accesses')ユーザーエージェントのみでの集計結果。
以上。
(2024.07.07)
(2024.07.07)
スポンサー リンク